Model Train-related Notes Blog -- these are personal notes and musings on the subject of model train control, automation, electronics, or whatever I find interesting. I also have more posts in a blog dedicated to the maintenance of the Randall Museum Model Railroad.
2022-01-22 - Conductor 2: Error Management
Category Rtac
We need to dwell a bit more on error management in Conductor 2. What is the current situation, versus what we really want?
In Conductor 1, error management is made ad-hoc by the script. For each individual route (branchlines vs mainline), there’s a timer, and the goal is that each shuttle should complete its travel within 5 minutes. The implementation is rather simple: the timer is started when the engine starts in either direction, and stopped when the engine reaches the target block. If the timer expires, the global state is changed to error, which stops everything for that route. There is nothing in the script to get out of that error state. A manual reset (via the tablets) is necessary.
In Conductor 2, the error management should depend on the route manager. Here we’re only concerned with the shuttle “sequence” manager. We can decide to keep it as simple as it was in Conductor 1 -- namely that the route must complete in a given time.
The other thing we can do is take advantage of the block sequence, since we know which blocks the train must travel. The manager also keeps track of the train progression so in theory it knows which blocks must be occupied and more importantly which ones must be free. So we can also take advantage of that. Thus, upfront, the rules would be something like this:
- The current active block must be occupied.
- There should not be any inactive block occupied.
- This rule requires a caveat as a train traveling can temporarily occupy 2 blocks. To solve that, we add the notion of a “trailing” block, which is the block the train just exited -- it can be occupied, even though it’s not the active block.
- If the train is moving, it should change to the next expected block within a given time.
- That time should be configurable for each route. A large enough default (e.g. 5 minutes) would work, and we might want to tighten it per route.
So in essence we change the timer from “overall route timer” to “to the next block timer”. Each time a train enters a block, we restart the timer. If a train is stopped, we must also stop the timer.
If the “next block timer” expires, the route enters error mode.
Script wize, the choice is to have a layered error management:
- Each Route has its own error property: Self.Error.
- The route script can set it to true:
Self.Error = True - It cannot be set to false.
- Each Route has an OnError event function that can be implemented.
- The ActiveRoute also has an error property that is an OR combination of each sub-route’s error. Thus as soon as any route is in error, the larger ActiveRoute object is in error too.
- A global condition “ActiveRoute.Error -> …” can be defined.
- It is not possible to activate a Route or an ActiveRoute that is in error.
- Errors are fatal like in Conductor 1. There is no clearing of the error except doing a full reset. That’s a simplification that could be easily lifted.
Since the route manager is going to enforce that only the expected blocks are occupied, we also may want to define 2 more properties for a shuttle behavior:
- We defined the expected route blocks to monitor.
- We also could define unexpected route blocks… Blocks to monitor that the train should not reach.
- We also may want to define exceptions for these. For example in both Randall shuttles cases, it would be ok for the train to overrun its stopping blocks. In Conductor 1, there’s a rule that forces the train in reverse if that happens. This is, in essence, a recoverable error.
It’s worth keeping in mind that if we monitor non-route blocks, we don’t know for sure what is occupying them. The simplest option is to not monitor them as part of the manager, and let the script handle that.
For one thing, we miss the capacity to pause the route. In an ideal world if an unexpected monitor block becomes occupied, it would be nice to be able to pause the automation while operators rectify the situation. We can expect operators to have that kind of awareness as they lack proper feedback from the automation.
The shuttle overrun case is worth handling. Currently the behavior would be to have block “X then Y” occupied. But if we overrun, none of the expected blocks will be occupied. The manager would need to know what is the overrun block and where it fits in the block sequence, as well as know when the situation has been rectified.
For example for the Freight route we have:
- Normal: B311 → B321 → stop/reverse → B321 → B311.
- Overrun: B311 → B321 → (B330 overrun) → B321 → B311.
A possible syntax would be to describe this as:
- Normal: Self.Blocks = B311, B321, B311.
- Overrun: Self.Blocks = B311, B321 (overrun = B330), B311.
Or Self.Blocks = B311, B321, (recoverable B330 to B321), B311.
The first example of syntax makes B330 an extra annotation to B321, whereas the second one adds a potential node in the graph.
What is important is to realize we're building a graph with 2 nodes out of B321.
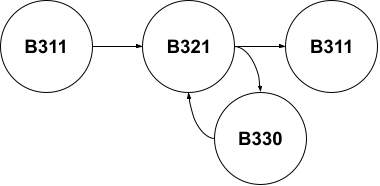
When viewed that way, B330 becomes a “normal” block in the sequence. That dictates it should not be treated as some exception, it’s just one of the two blocks that can be activated out of B321. The script engine just doesn’t know which one, and should accept both.
So we changed our linear “block list sequence” in a free “block graph”. That’s neat.
One important detail is that our “block graph” is not encoding the direction of the engine when changing between nodes.
That is something we may want to consider. See below.